IonRouter
Released 3mo ago
ML
|Optimization
|Robotics
|Entertainment
ionrouter.io
ionrouter.io

ionrouter.io
The Vision: Why IonRouter Exists
IonRouter is the high-performance inference layer for distributed GPU workloads. It addresses the critical bottleneck of high latency and inefficient hardware utilization in AI deployment. By optimizing how models interact with hardware, it enables real-time performance for demanding applications. Here are specific personas who benefit most:
- Robotics Engineers: Who require real-time VLM perception for autonomous movement and interaction.
- Video Pipeline Developers: Who need to manage multi-stream video analysis or text-to-video generation at scale.
- Game Developers: Who utilize on-demand asset generation and real-time AI integration within gaming environments.
The Engine: How the "Secret Sauce" Works
AI Technology: Optimization and Inference Engineering.
Input-Output Loop: Developers point their existing OpenAI-compatible client to the IonRouter API endpoint; the system then routes the request through the IonAttention engine to deliver high-speed model outputs with minimal overhead.
Innovation highlights:
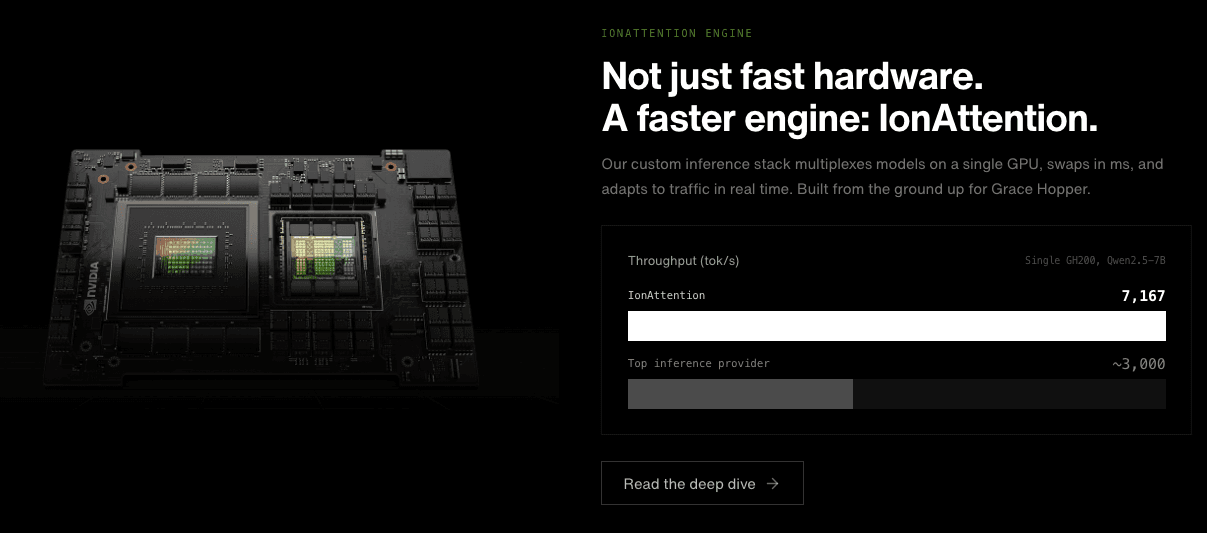
- IonAttention Engine: A custom inference stack built from the ground up for NVIDIA Grace Hopper superchips, allowing for model multiplexing on a single GPU.
- Millisecond Swapping: The ability to swap models in and out of GPU memory in milliseconds, adapting to traffic fluctuations in real time.
- High Throughput: Achieves up to 7,167 tokens per second on specific models, significantly outperforming standard inference providers.
The Toolkit: Capabilities & Connectivity
Flagship Features:
- Zero Code Changes: Offers a drop-in replacement for OpenAI API clients, requiring only a single line change to the base URL.
- Dedicated GPU Streams: Provides users with dedicated streams that ensure zero cold starts and consistent performance for custom LoRAs and finetunes.
Integrations: OpenAI Python SDK, TypeScript/Node.js environments, Go, and any framework supporting standard RESTful AI API calls.
The Proof: Market Trust
Status: Member of the NVIDIA Inception program and part of the W26 cohort.
- 7,167 tok/s: Demonstrated throughput on Qwen2.5-7B using a single GH200.
- 0ms Cold Starts: Guaranteed readiness for GPU streams, eliminating the typical lag associated with serverless GPU deployments.
- Multi-Model Efficiency: Proven capability to run five vision-language models (VLMs) concurrently on a single GPU.
The Full Picture: Value & Realism
| Pros | Cons |
|---|---|
| Industry-leading throughput and ultra-low latency. | Highly optimized for specific hardware (Grace Hopper), which may limit general cloud flexibility. |
| Seamless integration with existing OpenAI-based codebases. | As an emerging platform, the model library is still expanding compared to legacy providers. |
Pricing
- Language Models: Pay-per-million tokens (e.g., Qwen3.5 at $0.20 in / $1.60 out).
- Reasoning Models: Frontier models like GLM-5 at $1.20 in / $3.50 out per million tokens.
- Video Generation: Usage-based billing at approximately $0.00194 per GPU-second.
Frequently Asked Questions
Q1: Do I need to rewrite my application to use IonRouter?
A: No, it is designed as a drop-in replacement for any application currently using the OpenAI API format.
Q2: How does IonRouter handle "cold starts"?
A: Through the IonAttention engine and model multiplexing, the system maintains active streams to ensure 0ms cold starts for requests.
Q3: Can I deploy my own custom finetuned models?
A: Yes, the platform supports custom LoRAs and finetunes with dedicated GPU streams and per-second billing.